Scaling architecture diagramming with parallel agents and feedback-driven prompting
By
Kyle Barnett
Introduction
Diagramming applications is one of the most effective ways to know your domain, but the sheer volume of applications a team can own makes the task of diagramming all of them impossible to do individually and extremely daunting.
With the recent marriage of generative AI tools and software development, tasks that required significant manual effort are increasingly automated — enabling teams to shift their focus from repetitive implementation to higher-order design, architecture, and innovation. In practice, the hard part isn’t generating output; Instead, it’s orchestrating agents to optimize concurrency, while continuously improving prompts to accommodate a diverse range of applications.
The idea started here: come up with a way to run multiple agents at the same time, to reduce the time and effort it would take to diagram a team’s entire system.
Summary
I developed a parallelized agentic script that analyzes all source code and IaC for a group of related microservices and automatically generates architecture diagrams for each. Finally, it diagrams the whole system of applications and how they relate to each other.
Are the diagrams comprehensive? Not always. As AI is used to generate them, they need refinement to ensure accuracy and usefulness, but they provide a useful starting point for understanding complex system architectures.
Was this fun and interesting? Absolutely. What began as a diagramming project evolved into something far more compelling. As the experiment progressed, I found myself increasingly captivated by optimizing the agentic workflow itself rather than perfecting the diagrams. The real innovation emerged organically: a self-improving feedback loop where agents continuously version and refine their own prompts. Similar to the concept within systems/controls engineering, this mechanism allows the system to evolve autonomously as it encounters diverse applications across our company’s ecosystem, learning from each analysis to improve future runs.
An iterative approach
Having no real end goal except “have the AIs completely diagram our entire system architecture” and no set design, this experiment evolved significantly as it progressed and new technologies became available.
Phase 1: Proof of concept
To start, all the code needed to be accessible on a local disk for the agent runner to inspect and process. This would provide the majority of information needed to diagram our applications. From here a two-part plan was put into motion:
Individually analyze all the applications within the group
Combine / synthesize a full picture view of the system
These two parts were the genesis of the Individual Analysis Agent and the Synthesis Agent.
Early instructions directed the Individual Analysis Agents to only look at applications that they could identify the IaC repos for. Unfortunately, the project structure for pairing application repos and IaC repos together varied from team-to-team so, after a few attempted runs, it became obvious that the complexity of identifying the pairs was too much for the agent whose responsibility was supposed to be diagramming individual applications. This led to the creation of the Discovery agent.
Phase 2: Attempting to parallelize agents in windsurf
At the time this portion of the experiment was performed, the ability of chat agents to launch their own subagents had not been released to the IDE being used for development. This made concurrency a bit difficult. Since one of the main goals of this exploration was to get multiple Individual Analysis Agents running at the same time processing these applications, all the development through this point was merely opening different chat windows within Windsurf and pasting in prompts developed between the “Planning Agent” and I.
At this point 4 separate agents prompts were used to split up the work of establishing relationships between repositories, diagramming/analyzing applications, generating a full system diagram of all the applications, and coordinating/troubleshooting/improving the entire process:
Discovery agent – Responsible for discovering the relationships between our application repositories. It produces a list of applications that the Individual Analysis Agents would need to go through, where the entries looked like this:
### 11. nova-dashboard
- **App Repo:** `/Users/kyle-barnett/dev/AstroOps/nova-dashboard`
- **IAC Repo:** `/Users/kyle-barnett/dev/AstroOps/nova-dashboard-iac`
- **Match Type:** Exact name match
- **IAC Location:** Separate repository
- **🆕 Deployment Type:** EKS with Fleet
- **🆕 Namespace:** nova-dashboard
- **🆕 Team:** AstroOps
- **🆕 Environments:** testing, staging, production
- **🆕 Jenkins:** ✅ Found
- **🆕 Priority:** P0 - High (actively deployed)
- **Status:** ✅ Ready for analysis
Individual analysis agent – The diagrammer and analyzer. It would use information made by the Discovery Agent to locate all of the information about an application. Creating this agent was the most exciting one, because it offered the most opportunities for parallelization.
Synthesis agent – This was the end goal for the whole project. Once we had all the smaller diagrams and application relationships on an individual level, one last agent would go through all of them and piece them together into a set of diagrams that captured the complexities of the entire system.
Meta-coordinator / planning agent – At this point in the development process, this agent was responsible for helping improve the prompts created for each agent. As each agent finished running, it would be asked for improvements surrounding its prompt and then this agent would update the prompt for the agent giving the feedback.
(Honorable mention) Monitoring agent – This agent was supposed to monitor the task queue and report real-time analytics on the state of the process. A python script quickly seemed like a more appropriate solution to monitoring.
Issues did arise, which helped clarify the scope of applications to be diagrammed. By establishing a clear definition of the intended applications for inclusion, we ensured that repositories such as shared libraries, testing and lower environment applications, and legacy systems were appropriately managed within the process. This led to the inclusion of additional repos for our environmental deployments and the Discovery Agent coming up with its own priority classification system for applications with the highest priority being a production deployed.
Originally, the chat window used for overall planning and conversation was referred to as the “Planning Agent” but as time went on, human error crept in and chat windows were mixed up with each other. Prompts were given to it that weren’t meant for it, and its role/responsibilities overlapped with the Meta-Coordinator Agent. Both agents ended up existing as two separate but similar prompts that were tough to distinguish from one another.
Overall, two Individual Analysis agents were able to run at the same time and got a pretty good albeit manually managed flow of analysis going.
Phase 3: Experimenting with Devin CLI
After reading about Devin CLI, many pain-points around parallelization became easier to manage. There was no need any longer to manage four different chat windows at the same time, constantly trying to organize them in a way that allowed for easy recognition of what agent lived where and with what context. Now the same could be done with terminal windows!
large
Working with this new technology, the main constraint on productivity became unfamiliarity with permission settings. While working in “Normal” permission mode, every terminal command the CLI wanted to perform needed confirmation from the user before running it.
At this point, each agent’s invocation was translated into its own task within a file-based task queue. Agents would then create a task-queue.lock file before claiming tasks in an attempt to prevent concurrency issues within the queue file.
Phase 4: Near autonomous parallelization
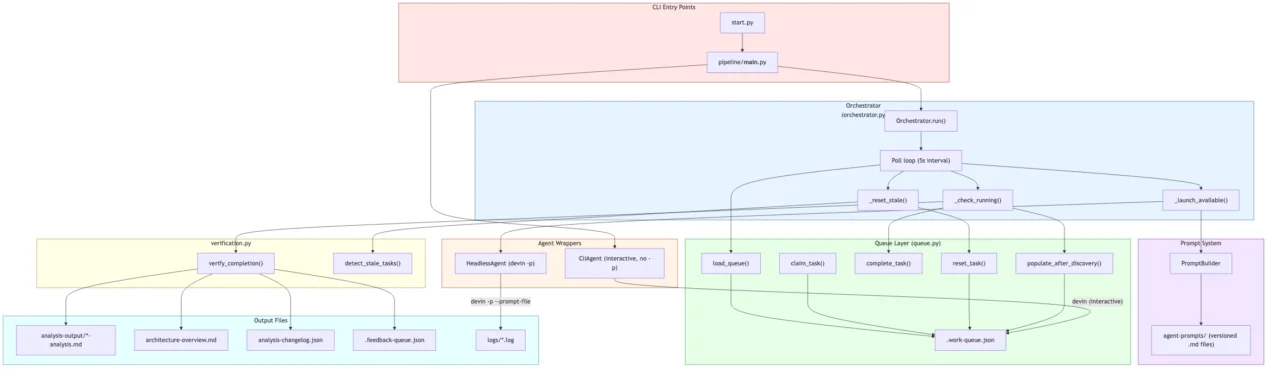
The current version of this project has been reduced to running as a singular python script. The script kicks off a Startup Agent that assists the user in cloning all the repositories for the microservices. Upon exiting the Devin CLI agent, an orchestrator class manages headless versions of the rest of the agent types while maintaining the file-based task queue and kicking off the associated agent for each task (discovery, analysis, synthesis, and feedback). Each agent was launched with a combined prompt + task created by the orchestrator depending on what is available in the queue.
The following diagram is a self-analysis of the project, performed by feeding a prompt into the Startup Agent where it was instructed to analyze its own codebase by creating a symlink to the project root instead of cloning external repositories.
large
Parallelizing agent work
The key advantage of the parallelization became apparent during Phase 3 while adopting Devin CLI instead of conversing with multiple chat windows. The work/task queue that was developed allowed for a flow where any amount of Individual Analysis agents could be spun up as workers, processing applications from the queue. Here are some stats from a four-agent limited run against a group of 35 applications:
Phase
Time (min)
Percentage of Total Runtime
Repo cloning
6.2
10.9%
Discovery
9.0
15.8%
Individual Analysis
26.0
46.6%
Synthesis
4.8
8.4%
Feedback
11.0
19.3%
Total
57.0
–
The Individual Analysis phase completion time was 2-3 times higher than all other phases
Other phases were relatively comparable to each other
The script was run a second time against the same collection of applications with an increased maximum of concurrent agents to compare runtime (note: since feedback from the first run would have already been incorporated into the agent prompts, the second run potentially skews the results to be higher than they should be). A 2:1 ratio of applications to max Individual Analysis agents (20 overall) was used for the analysis:
Phase
Time (min)
Percentage of Total Runtime
GitLab repo cloning
6.2
15.2%
Discovery
8.9
21.8%
Individual Analysis
7.5
18.5%
Synthesis
10.8
26.5%
Feedback
7.3
18.0%
Total
40.7
–
The Individual Analysis phase is much more comparable to the other phases during the second run reducing from 46.6% of the total run to 18.5%
The overall run time was reduced by 28.5%
Interestingly the Synthesis phase took twice as long for the second run, exposing portion of the process that may need some improvement
Feedback-driven prompting
Feedback-driven prompting involves asking an agent for improvements to its original prompt based on the outcome of the task it was asked to perform. That feedback is then incorporated into that prompt for the next time it is utilized for a similar task.
One of the most interesting features implemented early on was a feedback loop between the agents and me. During Phase 2, while working in multiple chat sessions in Windsurf, every conversation with a chat agent started to naturally end with the question:
Do you have any feedback that could be used to improve your original prompt?
After memories had been created for each of the agents, all agents had knowledge of each other’s existence and the final chat command degraded to “any feedback for the planning agent?”. Nonetheless, each agent would come up with improvements to its prompting as different applications were analyzed. Their feedback was then dropped into the Meta-Coordinator agent’s chat window. On its own, the agent even started versioning each of the agent’s prompts.
Eventually, constantly asking agents for their feedback and adapting their prompts became a chore. This responsibility was subsequently delegated to the agents themselves. The Meta-Coordinator agent would now adapt the prompts of each of the individual agents, and the final assignment of every prompt was to output feedback on how well the prompt addressed the task assigned. Here is an example prompt snippet:
## POST-TASK SELF-REFLECTION (REQUIRED)
**Before exiting, you MUST write a feedback entry to the feedback queue file.
**Do NOT output any summary to the user before writing feedback.
With the incorporation of the task-queue into the design, it also felt natural to start a “feedback-queue” as well. Analyzing feedback added to this queue was also updated to be a task at the end of the run. Further refinement and splitting up of agent responsibilities led to the establishment of a Feedback Agent. The Feedback Agent’s sole purpose was to process agent feedback and update their respective prompts (this also led to the deprecation the meta-coordinator / planning agent).
This process was initially developed against different systems of StellarOps applications, which are architecturally similar to one another. Feedback from the agents tended to be minimal at times. However, after running the script against the AstroOps team’s applications, the volume and specificity of the feedback exploded due to the architectural differences from a vastly different application stack. The result was the 11-minute runtime listed above, making up 19.3% of the total runtime. Here is an analysis of the feedback-queues leftover from the StellarOps vs AstroOps run:
StellarOps feedback was largely self-congratulatory because the prompts already fit the TFC-only, EKS/EC2-homogeneous codebase well. AstroOps feedback was genuinely constructive because the codebase exposed real prompt blind spots (Lambda, desktop apps, MCP, multi-database patterns). The time estimate data was useful in both, but AstroOps’ prompt gap identification drove meaningful prompt evolution.
After rerunning the script against the AstroOps group a second time the following was recorded:
Phase
Time (min)
Percentage of Total Runtime
Comparison to First Run
GitLab repo cloning
8.2
13.4%
ignored
Discovery
10.0
16.3%
+11.1%
Individual Analysis
30.5
49.8%
+17.5%
Synthesis
5.3
8.7%
+12.2%
Feedback
7.2
11.8%
-34.8%
Total
61.2
–
+4.5%
At first glance the second run is shockingly worse. Confused, I ran an analysis:
Summary
The feedback DID help — for the 26 apps that both runs analyzed, AstroOps_2 was 298s (5 min) faster cumulatively, averaging 11.5s/app improvement. The per-app speedups are real: interstellar-mail-relay -60s, nebula-gateway -41s, asteroid-dodge-lambda -111s. AstroOps_2 was slower overall because of three compounding factors:
1. The v4.2 discovery found more (and harder) apps
The improved discovery prompt found 37 apps vs 35. The v4.1 discovery found several trivial/deprecated apps (mission-proto, stellar-commons, asteroid-identifier-iac) while v4.2 found more complex ones (quasar-engine, cosmos-db-ws, warp-drive-simulator-iac).
2. One outlier task dominated the analysis wall-clock
analysis-quasar-engine took 459s (7.6 min) — nearly 3x the average. It was the last analysis task to finish and extended the wall-clock by ~4.5 minutes. This single task that didn’t exist in AstroOps_1 accounts for almost the entire wall-clock difference. Without it, AstroOps_2 analysis wall-clock would have been ~26 min — the same as AstroOps_1.
3. The v4.2 prompts are 66% larger
The analysis prompt grew from 503 to 813 lines (19.5KB to 32.4KB). Every one of the 37 agents had to ingest ~13KB more prompt text. This adds a small per-task overhead that compounds across all tasks. The discovery prompt grew 39% too, adding ~1 min to that phase.
4. Feedback phase was actually much faster (-3.8 min)
The v4.2 feedback processing was 3.8 min faster than v4.1 (7.2m vs 11.0m), likely because the prompts were already better-tuned and there was less corrective work to do.
Net: The feedback made each individual analysis faster, but the improved discovery found harder apps and a single
outlier task blew out the wall-clock.
So similar to early POCs, multiple iterations are needed between full runs to adapt to unencountered patterns and correctly identify applications.
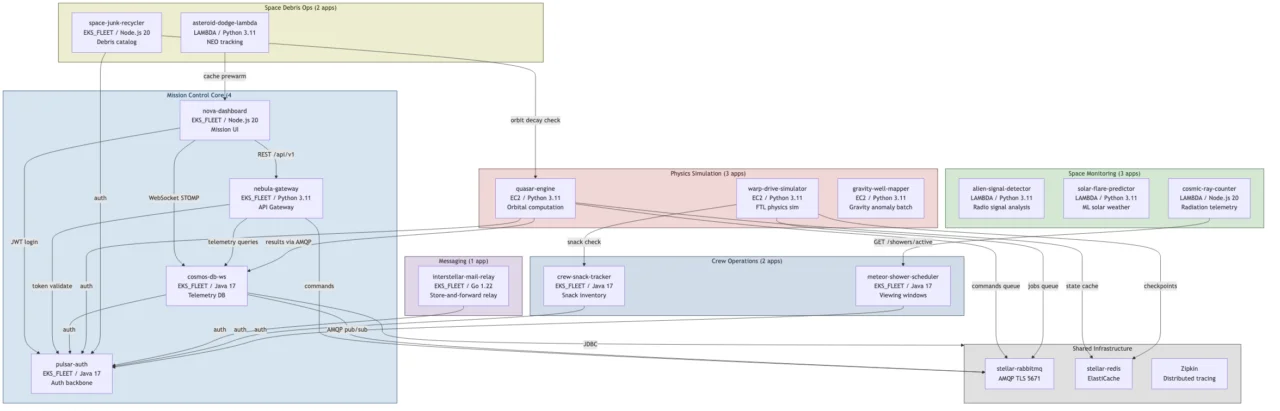
AstroOps System Overview
large
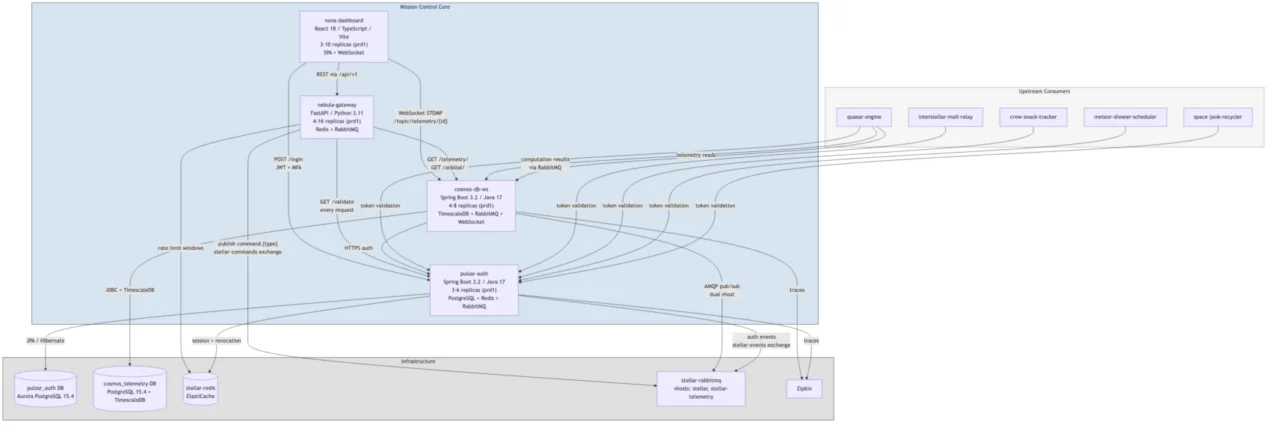
Zoomed-in Mission Control Core Diagram
large
Future improvements
The actual diagrams for each of the applications, as well as the system-wide diagrams, definitely need some work. Looking back at the initial agent chat history, there was a conversation about what the best diagramming method would be for an agent to analyze an application and its dependencies. It responded with Mermaid and described different application diagram types. The latter part of the response was forgotten, the answer to the question eventually becoming only “Mermaid diagrams.” Incorporating different diagram types to eliminate some of the noisiness on the diagrams, and then eventually splitting the analysis of an application from the creation of multiple types of diagrams would probably be a meaningful improvement.
Additionally, more work can be done to break down some of the agent prompts to help parallelize the process further. Breaking up the responsibilities of the Synthesis and Discovery agents could help bring to light an effective way to run multiple of them at the same time. The discovery process already works with a list of repositories, so splitting identification work should be relatively easy and reduce the consistent 9-10 minutes for that phase. The bigger problem to tackle would be how to run multiple Synthesis agents. Since that task is cumulative in nature, a lot more thought may be needed to break it down into smaller chunks. The Individual Analysis agents can also be broken down further to more effectively specialize their analysis between application types.
Once the process has been refined further, it would be worth exploring how feasible it would be to run it against the organization’s full application portfolio — and how quickly it could complete.
Conclusion
Incorporating feedback-driven prompting into an agentic ecosystem is a must for creating an adaptive, increasingly autonomous system. As prompts grow and agents start taking on overly broad tasks, taking a step back and breaking down their responsibilities allows for opportunities for additional concurrency. Traditional software development principles still apply when developing agentic software!
As the lines between public and private markets continue to blur, leaders are facing a familiar foe: fragmented data. When systems don’t talk to one another, the resulting manual workarounds and data gaps do more than just waste time—they create genuine risk in valuation and oversight.
Effectively adding AI trading technology to your risk conversations requires more than just a single agent operating as your AI Assistant. An effective AI team is made up of a variety of specialized agents that work together, designed, controlled and orchestrated by their human leader to tackle the multi-step and multi-role activities that are part of real-life trading and portfolio management.
Join us for a 30-minute webinar to see how Beacon by CWAN Power & Gas enables energy trading firms to deploy sophisticated energy risk management strategies. This webinar will include an in-depth product walkthrough with real use cases and scenarios.