Clearwater Performance & Risk: Turning Data into Insight
Clearwater’s performance and risk reporting capabilities, designed to help you better understand results, identify trends, and proactively manage portfolio exposure.
Videos
by Rany ElHousieny
After managing a team building a complex API Gateway and Developer Portal (1,200+ APIs across 6 acquired tech stacks), I ran into a problem that I suspect every engineering manager faces: institutional knowledge was scattered everywhere. Meeting notes in one place, architecture decisions in another, sprint data in JIRA, credential docs in a wiki, and the real decisions lived in people’s heads.
When a new developer joined the team, onboarding took weeks. When I needed to answer a leadership question about our progress, I had to dig through 10 different sources. When the AI coding assistant tried to help, it hallucinated because it had no grounded context.
So I built a system that solved all three problems at once. This article walks you through how I did it and how you can do the same for your team.
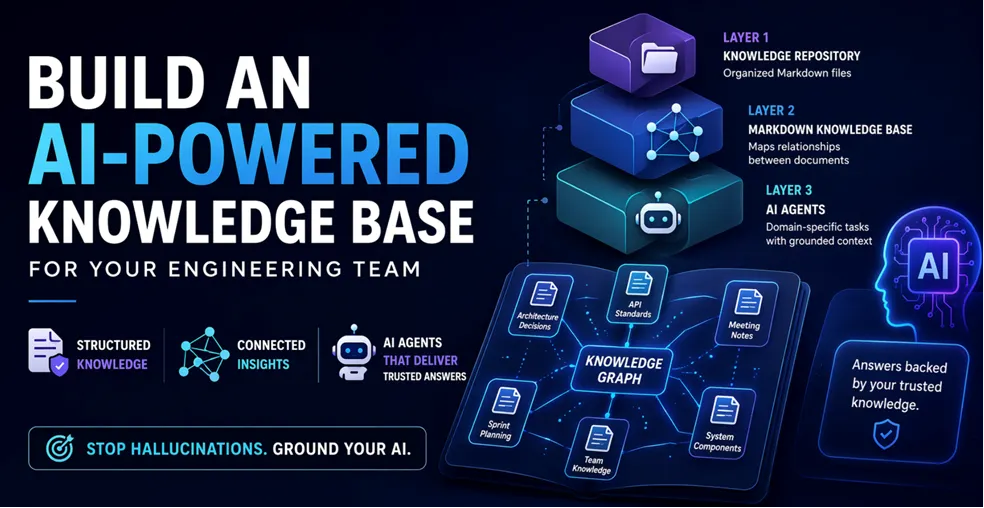
The system has three layers that build on each other:
Layer 1: Knowledge Repository – A structured directory of markdown files organized by authority level and topic.
Layer 2: Markdown Knowledge Base – A single markdown file that maps relationships between all documents, making the entire knowledge base navigable by both humans and AI agents.
Layer 3: AI Agents – Specialized agents that consume the knowledge base and perform domain-specific tasks with grounded, evidence-based responses.
Let me walk through each layer with real examples from the system I built.
The foundation is a well-organized directory of markdown files. Here is the structure I use:
project-root/
|– START_HERE.md # Onboarding entry point
|– AGENTS.md # Instructions for AI agents
|– CLAUDE.md # Project rules for Claude
|– Knowledge/
| |– KNOWLEDGE_BASE.md # The Knowledge Base map (Layer 2)
| |– Source of Truth/ # Tier 1: Leadership-approved docs
| |– 00_project_context.md # Tier 2: Core knowledge files
| |– 01_component_a.md
| |– 02_component_b.md
| |– meetings/ # Meeting notes
| |– TEAM/ # Team profiles
| |– Public_API_Standards/ # Domain-specific knowledge
| |– archive/ # Historical docs (not authoritative)
|– Planning/
| |– Q2_Sprint_1/ # Sprint planning files
| |– Q2_Sprint_2/
|– Generated/ # AI-generated artifacts
|– prompts/
| |– templates/
| |– AI Agents/ # Agent prompt definitions
|– .claude/
| |– commands/ # Slash commands
| |– skills/ # Auto-activating skills
Not all documents are equal. I organize them into tiers:
Tier 1: Source of Truth – Leadership-approved documents that define the project’s direction. These are read-only for AI agents. Examples: team kickoff notes, scorecards, VP directives, architecture decisions. If an AI agent contradicts a Tier 1 document, the agent is wrong.
Enforcement happens at three points: (1) each agent’s session initialization forces it to read Source of Truth files first, (2) the rules file (CLAUDE.md) instructs agents to cite Tier 1 files with file:line evidence for any authoritative claim, and (3) the user verifies answers by clicking through to the citation. When cited evidence doesn’t support the claim — or when it contradicts a Tier 1 file the user knows — the user catches it. The tier system converts silent hallucination into a visible, citable mismatch that a reviewer can spot.
Tier 2: Core Knowledge – Foundational technical documents that explain the system’s components. Examples: API gateway strategy, identity layer design, MCP server architecture. These are the “textbook” for your project.
Tier 3: Implementation & Analysis – Sprint planning files, meeting notes, generated reports. These are working documents that change frequently.
Tier 4: Historical/Archive – Old documents kept for reference. Explicitly marked as non-authoritative to prevent AI agents from citing outdated information.
This is the part that ties everything together. The Knowledge Base is a single markdown file (Knowledge/KNOWLEDGE_BASE.md) that maps relationships between all documents in the knowledge base.
# Project Knowledge Base
## Document Hierarchy & Authority
### Tier 1: Source of Truth (READ ONLY)
Source of Truth/
|– team_kickoff.md [PRIMARY – Vision, roadmap, team structure]
|– scorecard.md [CRITICAL – Success metrics & milestones]
|– vp_directive.md [CRITICAL – Priorities & ownership]### Tier 2: Core Knowledge
00_project_context.md [Foundation – Start here]
01_api_gateway.md [Component – Gateway strategy]
02_identity_layer.md [Component – Identity & auth]
03_mcp_servers.md [Component – MCP integration]## Concept Clusters
### Authentication & Credentials
– START_HERE.md > “Developer Auth” section
– 02_identity_layer.md > full IAM design
– 15_auth_standard.md > implementation spec
– Environment variables file > token storage (NEVER commit)### Sprint Planning
– Planning/Q2_Sprint_1/ > current sprint
– Generated/PROGRESS_TRACKER.md > status
– Knowledge/21_quality_standards.md > story requirements## Relationship Map (Mermaid)
(mermaid diagram showing document connections)
When an AI agent receives a question like “What is our authentication strategy?”, it:
Without the Knowledge Base, the AI agent would have to search every file in the repo, likely miss important context, and potentially hallucinate based on outdated files in the archive.
The Knowledge Base needs to stay current. I use two mechanisms:
This is where the system becomes powerful. Each AI agent is a specialized prompt that consumes the Knowledge Base and performs domain-specific work.
I follow a single source of truth architecture for agents:
prompts/templates/AI Agents/ # Source prompts (full definitions)
.claude/commands/<name>.md # Thin wrappers (invoke via /slash-command)
.claude/skills/<name>/ # Skill definitions (auto-activating)
The rule is simple: only edit the source prompts. The workflow wrappers and skills are thin pointers. This prevents content drift between multiple copies of agent instructions.
Every agent prompt follows this structure:
# Agent Name
## Role
One paragraph defining what this agent does.## Session Initialization (MANDATORY)
1. Read START_HERE.md
2. Read Knowledge/KNOWLEDGE_BASE.md
3. Check Generated/PROGRESS_TRACKER.md
4. Read relevant Source of Truth files## Core Capabilities
– Capability 1 with specific instructions
– Capability 2 with specific instructions## Rules
– Evidence-based responses only (cite file:line)
– Mark confidence levels (HIGH/MEDIUM/LOW)
– Never speculate about system behavior
– Follow the authority hierarchy (Tier 1 overrides Tier 2)## Knowledge Sources
(list of files this agent should read)## Tools Available
(list of tools/scripts this agent can use)
Here are some of the agents in the system and what they do:
Developer Agent – Writes code, implements features, follows the project’s coding standards. Knows the repo structure, CI/CD pipeline, and testing patterns.
Scrum Master Agent – Manages sprint ceremonies, creates JIRA tickets, tracks velocity, generates sprint review decks. Fetches live data from JIRA APIs.
Security Engineer Agent – Reviews code for security issues, knows the IAM integration patterns, validates authentication flows.
Gateway Expert Agent – Deep specialist in the API Gateway infrastructure. Knows Terraform configs, Nginx routing rules, OpenAPI specs, and service onboarding procedures.
Service Learning Agent – Onboards new service domains. Clones a repo, analyzes it, generates a Knowledge Base and an AI Agent for that service.
Agents become truly useful when wrapped in workflows that developers can invoke with slash commands:
—
description: Generate sprint review slides from JIRA data
—# /sprint-review-slides
## Step 1: Fetch data from JIRA
(automated script that pulls velocity, tickets, accomplishments)## Step 2: Update the generator script
(copy from previous sprint, update SPRINT dictionary)## Step 3: Generate the deck
python3 Planning/Q2_Sprint_N/generate_sprint_review.py## Step 4: Verify output
(check the generated .pptx file)
A developer types /sprint-review-slides and the agent handles everything: fetching JIRA data, generating PowerPoint slides, and saving the output.
Create a single entry point file that answers these questions:
This file should be readable in under 5 minutes and give someone enough context to start contributing.
Take your existing documents (wiki pages, design docs, meeting notes) and organize them into the tiered structure:
mkdir -p Knowledge/Source\ of\ Truth
mkdir -p Knowledge/meetings
mkdir -p Knowledge/TEAM
mkdir -p Knowledge/archive
mkdir -p Planning
mkdir -p Generated
mkdir -p prompts/templates/AI\ Agents
Move your most important documents into Source of Truth/. Convert wiki pages to markdown. Date-prefix your meeting notes.
Create Knowledge/KNOWLEDGE_BASE.md with:
1. A list of every document organized by tier
2. One-line descriptions for each file
3. Concept clusters grouping related files
4. A Mermaid diagram showing relationships
Start simple. You do not need to map every relationship on day one. The Knowledge Base grows organically as you add documents and discover connections.
Pick the task your team does most often (probably sprint planning or code review) and create an agent for it:
1. Write the agent prompt in prompts/templates/AI Agents/MY_AGENT.md
2. Create a slash command in .claude/commands/my-agent.md
3. Test it by invoking the slash command
4. Iterate based on what the agent gets wrong
Create CLAUDE.md (or .claude/rules.md, or the equivalent rules file for your AI tool) with rules like:
Rules are what turn a generic AI assistant into a grounded team member.
Create workflows for keeping the system current:
After running this system for several months with a team of 5 developers:
Onboarding time dropped from weeks to hours. New developers read START_HERE.md and the Knowledge Base, then the agent answers their questions with cited sources.
Sprint review prep went from 2 hours to 5 minutes. The /sprint-review-slides workflow pulls live data from JIRA and generates the entire PowerPoint deck.
Decision traceability improved dramatically. Every architecture decision is documented, cited in the Knowledge Base, and available to every agent. No more “I think we decided X in that meeting last month.”
AI agent accuracy improved significantly. With the Knowledge Base providing grounded context, agents stopped hallucinating about system behavior and started citing real evidence.
1. Do not try to document everything at once. Start with Source of Truth and the 5 most important knowledge files. Grow from there.
2. Do not skip the authority hierarchy. Without tiers, AI agents treat a random meeting note with the same weight as a VP directive. That leads to bad answers.
3. Do not let the Knowledge Base go stale. Build the maintenance habit into your workflows. If the Knowledge Base is outdated, AI agents make outdated recommendations.
4. Do not duplicate content across agent prompts. Use a single source of truth for each agent definition. Wrappers should be thin pointers, not copies.
5. Do not forget the rules file. Without rules, AI agents default to generic behavior. Rules are what make them follow your team’s standards.
The simplest starting point is three files:
1. START_HERE.md – Your project’s entry point
2. Knowledge/KNOWLEDGE_BASE.md – Document map with tiers and relationships
3. AGENTS.md – Instructions for AI agents entering your workspace
From there, add knowledge files as you go, build agents for repetitive tasks, and create workflows for your most common operations. The system compounds over time — every document you add makes every agent smarter.
https://www.linkedin.com/pulse/copy-how-knowledge-graphs-transform-genai-code-from-rany-jml7c

Rany ElHousieny is an Engineering Leader at Clearwater Analytics with over 30 years of experience in software development, machine learning, and artificial intelligence. He has held leadership roles at Microsoft for two decades, where he led the NLP team at Microsoft Research and Azure AI, contributing to advancements in AI technologies. At Clearwater, Rany continues to leverage his extensive background to drive innovation in AI, helping teams solve complex challenges while maintaining a collaborative approach to leadership and problem-solving.